모두를 위한 머신러닝 / 딥러닝 강의: hunkim.github.io/ml/
Multi-variable linear regression
우리는 이제 변수 3개에 대한 출력이 1개인 데이터 셋을 학습시키려한다.
변수가 3개라면 각각의 변수에 대한 weight(가중치)가 존재할 것이고
이 가중치가 곱해진 변수들의 합은 Hypothesis(가설, 직선)을 나타낸다.


cost를 정의하고 optimizer를 Gradient Descent Algorithm 을 사용하여 minimize cost를 구하도록 설정하였다. 이제 train을 tf.Session().run(train)을 실행하면 cost는 최소를 구하도록 operation할 것이다.
그리고 학습과정에서 cost와 hypothesis값들의 변화를 출력하기 위해 변수에 값을 담아 출력하는 형태이다.
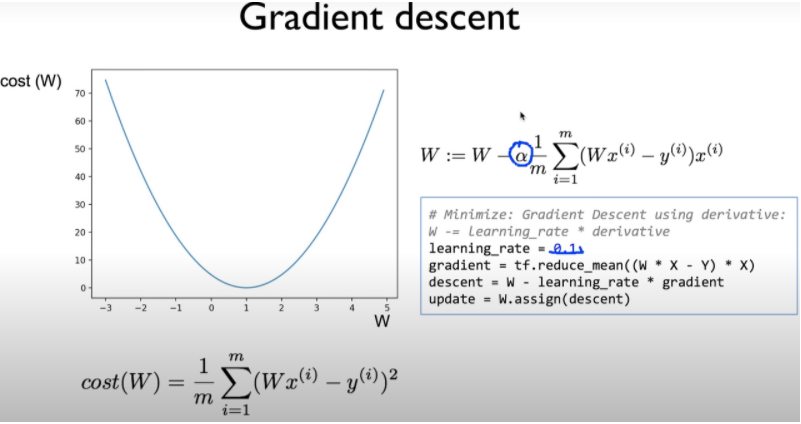
그런데 여기서 learning_rate는 무엇일까?
『Linear regression이나 logistic regression의 방법을 사용할 때 cost function을 최소화시키기 위해서 우리는 Gradient descent algorithm을 사용했다. Gradient descent는 기울기의 크기가 줄어드는 쪽으로 가는 것이 cost function이 최소가 되는 지점을 찾아간다는 생각에서 나온 알고리즘이다. Gradient descent algorithm을 사용할 때 cost 값의 미분한 값 앞에 알파라는 값이 오게 되는데 이 값이 Learning rate이다. Learning rate은 어느 정도의 크기로 기울기가 줄어드는 지점으로 이동하겠는가를 나타내는 지표이다. 그래프 상에서 이동하게 만드는 step의 크기를 조절한다고 할 수 있다.
만약 Learning rate의 값이 크다면 어떻게 될까? 처음 출발에는 기울기가 줄어드는 지점으로 이동을 하겠지만 어느 지점에서 최솟값에 도달하기 보다는 그 값을 넘어서 그래프의 반대편으로 지점이 이동할 수 있다. 이건 step의 간격이 너무 커서 발생하는 결과이다. 또한 이러한 차이가 계속 발생하게 되면 오히려 최솟값에 도달하기 보다는 그래프를 벗어나는 결과 값을 가지게 만들 수도 있다. 이러한 경우를 overshooting이라고 한다. 』
출처: https://copycode.tistory.com/166 [ITstory]
출력값

출력에서 cost의 값은 점점 최소를 찾아갔고, 출력Y에 대한 예측은 실제 측정된 값과 비교해보면 매우 흡사해지고 있음을 확인하였다.
But, 이런 방법은 사용하지 않는다.


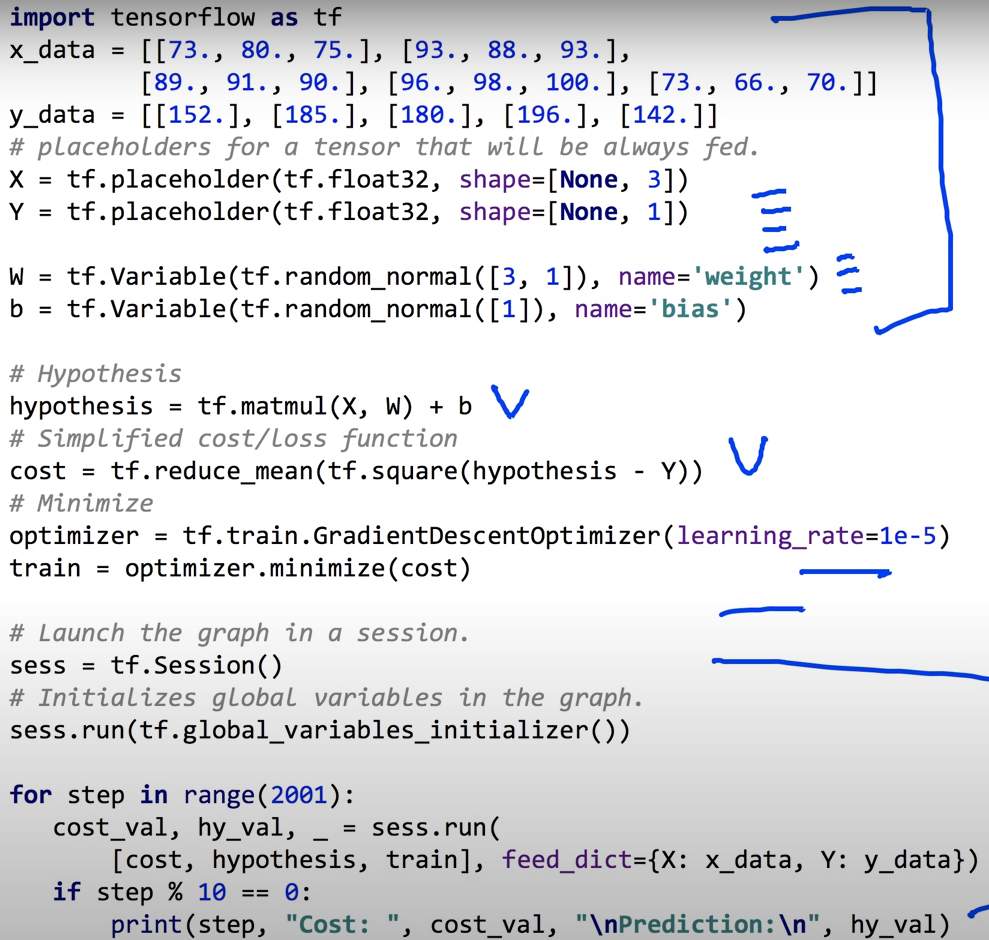
- x_data는 instance(데이터 묶음)단위로 관리한다.
- 모델을 만들때 사용할 X, Y에서 주의할 점이 shape이다.
- 첫 번째 항인 None는 총 데이터의 묶음인 instance의 갯수를 의미하는데 갯수에 제한이 없게 두는 것이다.
- 두 번째 항인 3은 한 instance당 데이터의 수(종속변수의 갯수)를 의미한다.
- b는 상수항이고, W의 경우 3행 1열 데이터이기에 다음과 같이 설정하였다.
- tf에서 matmul(메트릭스 곱)으로 연산하여 hypothesis를 구하였다.
다음 시간에는 많은 데이터를 기재하는 것이 힘들기에 파일에 저장하고 이를 불러오는 작업에 대해 공부해 볼 것이다.
'ETC > 머신러닝, 딥러닝 실습' 카테고리의 다른 글
| 3-3. Loading Data from File (파일데이터 읽어오기) (0) | 2020.10.31 |
|---|---|
| 3-1. 여러개의 입력(feature)의 Linear Regression 개념 (0) | 2020.10.29 |
| 2-6. Linear Regression cost함수 최소화 구현(by TensorFlow) (0) | 2020.10.29 |
| 2-5. Linear Regression cost함수 최소화 개념 (0) | 2020.10.29 |
| 2-4. Linear Regression by Tensorflow (선형회귀 구현) (0) | 2020.10.28 |