모두를 위한 머신러닝 / 딥러닝 : hunkim.github.io/ml/

지난 시간 복습
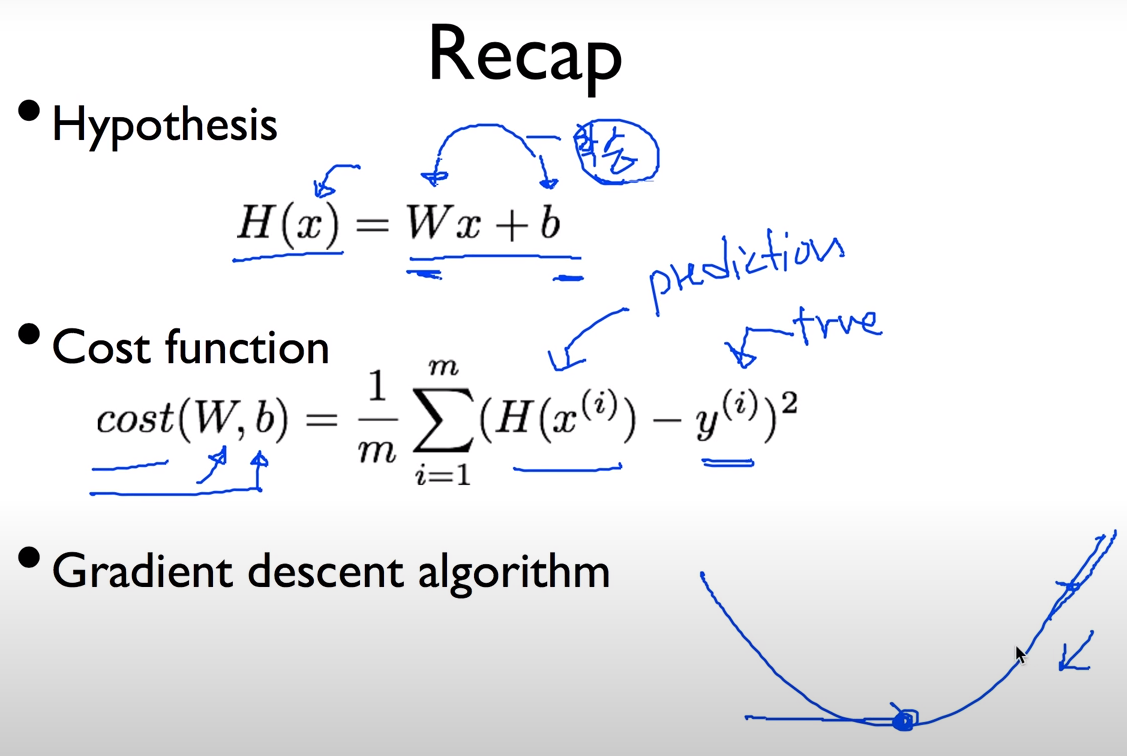
- Hypothesis (가설, 직선) : Weight와 bias의 값을 학습하게 된다.
- Cost function (cost,loss를 어떻게 정의하는가) : W와 b의 함수이다. 예측값과 실제값의 차이의 제곱평균을 구해서 cost를 구한다.
- Gradient descent algorithm (cost를 최소로하는 알고리즘) : 그 cost의 경사면을 따라 감소하는 방식의 알고리즘
여러개의 입력(feature)의 Linear Regression 개념
Multivariable Linear Regression
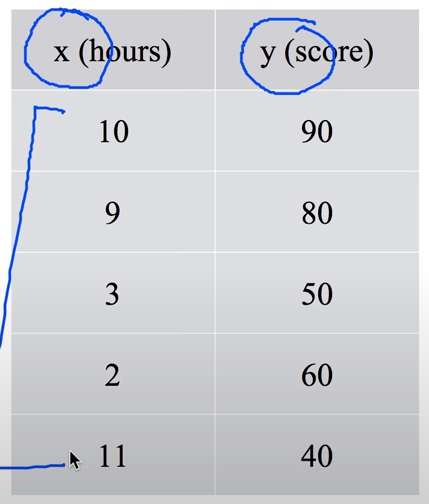
기존의 데이터는 하나의 Input에 대해서 모델을 만들고 학습을 시켜왔다.
But, 실제는 여러개의 데이터의 얽히고 섥힌 데이터들 투성이다.

이런 경우 Hypothesis와 cost들은 어떻게 식을 정의할까?? 간단하다 미지수를 늘린다.


매우 많아지면 다음과 같다.

But, 데이터가 많아지면 식과 항이 방대해져서 관리하기가 힘들어진다.
해결법 --> Matrix
식의 표현이 간단해진다.

???왜 굳이 앞에 X를 두었을까???왜 행렬을 사용했을까???
x1, x2, x3는 결국 주어지는 실제 데이터이고 결국 최적의 값을 구하는 것은 W(weight)이다.
우리에게 변수는 결국 W와 b임을 잊지말자.
그리고 데이터의 구조를 행렬의 구조와 맞추어 사용할 때 용이하기에 그렇다.
데이터 그대로 행렬곱셈만하면 각각의 instance에 대한 Hypothesis를 구할 수 있다.
(하나의 행은 한 묶음을 나타내고 이를 intance라고 부른다.)

m x n 행렬을 [m, n]이라고 표시를 한다면
- X의 경우 현재 데이터묶음(instance)의 갯수가 5개, Variable의 갯수가 3개인 경우이다. [5, 3]
- H(X)는 출력을 나타내고 Linear Regression은 출력이 하나이다. 그렇다면 각각의 instance에 대해 출력이 1개이기에 [5, 1]로 표시된다.
- 우리는 W(weight)가 얼마나 되는가를 결정 해야 하는데, 행렬의 곱셈 주고에 의해 [3, 1]이다. 이것은 무엇을 의미하는가? 3개의 변수를 통해 각각의 비중으로 무게치를 결정하기에 3개의 변수가 1개의 Weight를 결정한다는 의미이다.

일반화를 해보면 다음과 같다.
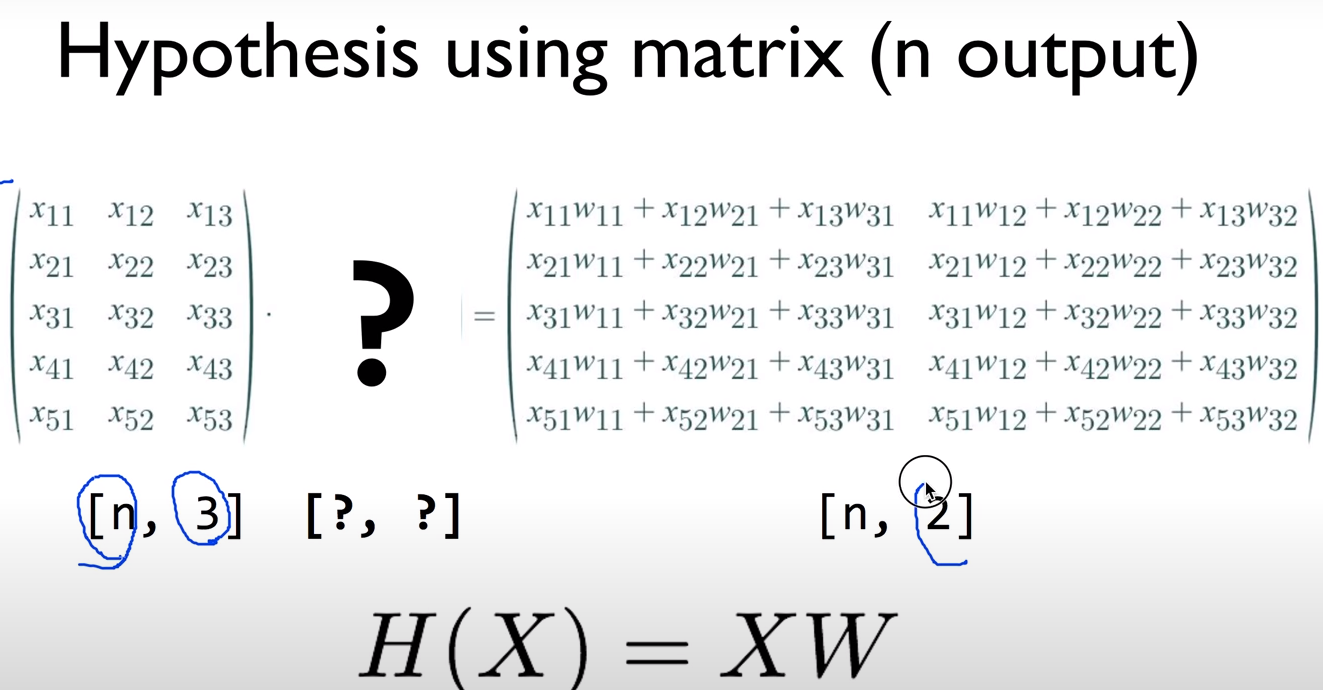
해석해보자
- 현재 data set의 경우 데이터의 묶음(instance)가 n개이고 variable은 3개이다.
- 우리는 해당 instance에 대해 2개의 출력값을 낼 것이다. 이는 3개의 variable로 부터 2개의 output을 내는것이다
- 그렇다면 각각의 instance에 대해 두개의 weight가 존재해야하고 W는 3행2열의 행렬이 되는 것이다.
주의할 점

이론에서와 구현에서의 식 구조가 다르다. 이는 행렬을 사용함에 있어서 data set의 구조를 바꾸지 않고 instance와 variable에 대한 연산을 바로 쓰는 편리함이 있기에 그러하다. 요거 주의하고 넘어가자
이상!! 오늘도 감코!!
'ETC > 머신러닝, 딥러닝 실습' 카테고리의 다른 글
| 3-3. Loading Data from File (파일데이터 읽어오기) (0) | 2020.10.31 |
|---|---|
| 3-2. 여러개의 입력의 Linear Regression 구현 (by Tensorflow) (0) | 2020.10.30 |
| 2-6. Linear Regression cost함수 최소화 구현(by TensorFlow) (0) | 2020.10.29 |
| 2-5. Linear Regression cost함수 최소화 개념 (0) | 2020.10.29 |
| 2-4. Linear Regression by Tensorflow (선형회귀 구현) (0) | 2020.10.28 |